说明:
对不起,我竟然用了一个夺人眼球的标题;我会尽量从一个程序员的角度来阐述OpenCL,目标是浅显易懂,如果没有达到这个效果,就当我没说这话;子曾经曰过:不懂Middleware的系统软件工程师,不是一个好码农;1. 介绍
以人工智能场景为例来理解一下,假如在某个AI芯片上跑人脸识别应用,CPU擅长控制,AI processor擅长计算,软件的flow就可以进行拆分,用CPU来负责控制视频流输入输出前后处理,AI processor来完成深度学习模型运算完成识别,这就是一个典型的异构处理场景,如果该AI芯片的SDK支持OpenCL,那么上层的软件就可以基于OpenCL进行开发了。
话不多说,看看OpenCL的架构吧。
2. OpenCL架构OpenCL架构,可以从平台模型、内存模型、执行模型、编程模型四个角度来展开。
2.1 Platform Model平台模型:硬件拓扑关系的抽象描述
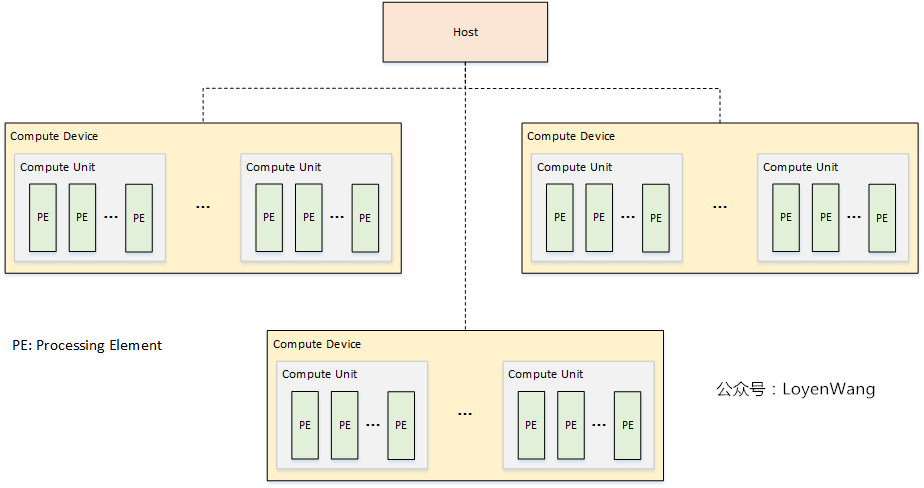
执行模型:Host如何利用OpenCL Device的计算资源完成高效的计算处理过程
ContextOpenCL的Execution Model由两个不同的执行单元定义:1)运行在OpenCL设备上的kernel;2)运行在Host上的Host program;其中,OpenCL使用Context代表kernel的执行环境:

Context包含以下资源:
Devices:一个或多个OpenCL设备;Kernel Objects:OpenCL Device的执行函数及相关的参数值,通常定义在cl文件中;Program Objects:实现kernel的源代码和可执行程序,每个program可以包含多个kernel;Memory Objects:Host和OpenCL设备可见的变量,kernel执行时对其进行操作;NDrange
有两种方式来找到work-item:
通过work-item的全局索引;先查找到所在work-group的索引号,再根据局部索引号确定;以一维为例:

以二维为例:
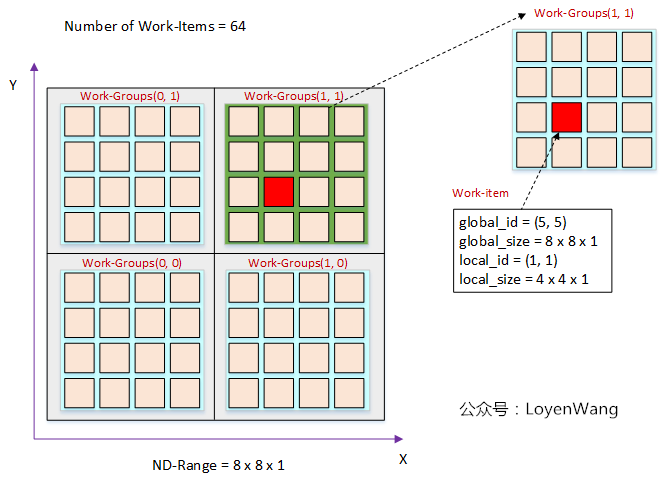
三维的方式也类似,略去。
2.3 Memory Model内存模型:Host和OpenCL Device怎么来看待数据
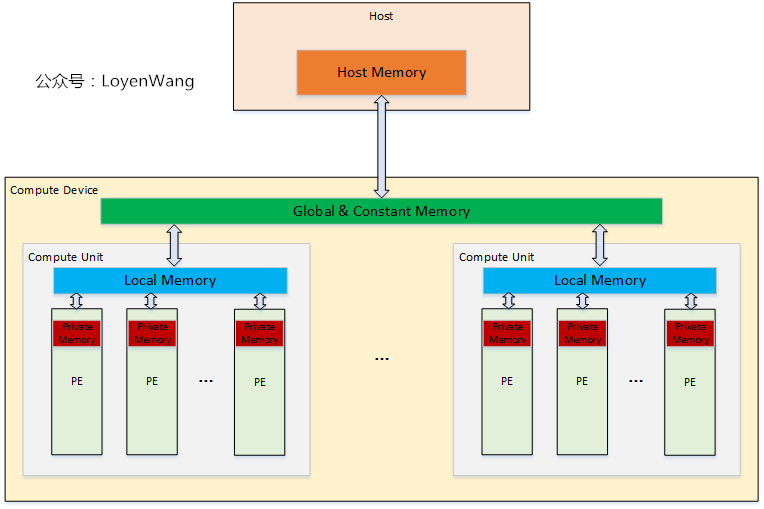
OpenCL的内存模型中,包含以下几类类型的内存:
Host memory:Host端的内存,只能由Host直接访问;Global Memory:设备内存,可以由Host和OpenCL Device访问,允许Host的读写操作,也允许OpenCL Device中PE读写,Host负责该内存中Buffer的分配和释放;Constant Global Memory:设备内存,允许Host进行读写操作,而设备只能进行读操作,用于传输常量数据;Local Memory:单个CU中的本地内存,Host看不到该区域并无法对其操作,该区域允许内部的PE进行读写操作,也可以用于PE之间的共享,需要注意同步和并发问题;Private Memory:PE的私有内存,Host与PE之间都无法看到该区域;2.4 Programming Model
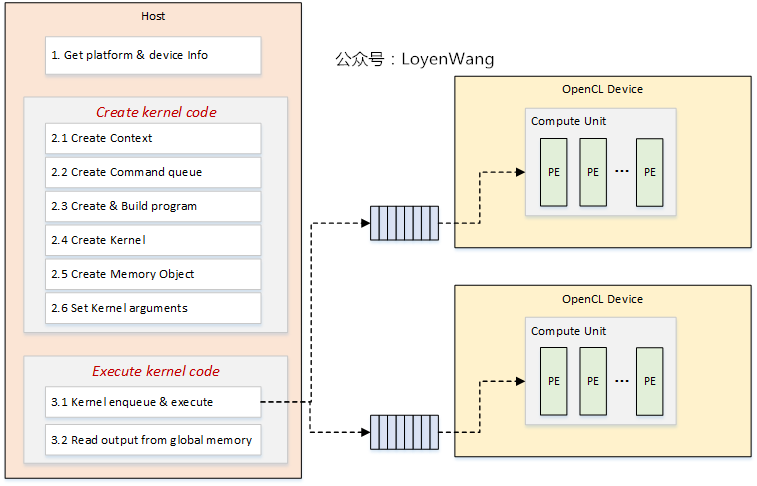
下边来一个实际的代码测试跑跑,Talk is cheap, show me the code!
4. 示例代码测试环境:Ubuntu16.04,安装Intel CPU OpenCL SDK(opencl_runtime_16.1.2_x64_rh_6.4.0.37.tgz);为了简化流程,示例代码都不做容错处理,仅保留关键的操作;整个代码的功能是完成向量的加法操作;4.1 Host端程序#include #include #include #include const int DATA_SIZE = 10;int main(void){/* 1. get platform & device information */cl_uint num_platforms;cl_platform_id first_platform_id;clGetPlatformIDs(1, &first_platform_id, &num_platforms);/* 2. create context */cl_int err_num;cl_context context = nullptr;cl_context_properties context_prop[] = {CL_CONTEXT_PLATFORM,(cl_context_properties)first_platform_id,0};context = clCreateContextFromType(context_prop, CL_DEVICE_TYPE_CPU, nullptr, nullptr, &err_num);/* 3. create command queue */cl_command_queue command_queue;cl_device_id *devices;size_t device_buffer_size = -1;clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, nullptr, &device_buffer_size);devices = new cl_device_id[device_buffer_size / sizeof(cl_device_id)];clGetContextInfo(context, CL_CONTEXT_DEVICES, device_buffer_size, devices, nullptr);command_queue = clCreateCommandQueueWithProperties(context, devices[0], nullptr, nullptr);delete [] devices;/* 4. create program */std::ifstream kernel_file("vector_add.cl", std::ios::in);std::ostringstream oss;oss